本文是在 Pthreads 学习过程中产生的入门级教程。
引入
hello,world
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
const int MAX_THREADS = 64;
/* Global variable: accessible to all threads */
int thread_count;
void Usage(char* prog_name);
void *Hello(void* rank); /* Thread function */
/*--------------------------------------------------------------------*/
int main(int argc, char* argv[]) {
long thread; /* Use long in case of a 64-bit system */
pthread_t* thread_handles;
/* Get number of threads from command line */
if (argc != 2) Usage(argv[0]);
thread_count = strtol(argv[1], NULL, 10);
if (thread_count <= 0 || thread_count > MAX_THREADS) Usage(argv[0]);
thread_handles = malloc (thread_count*sizeof(pthread_t));
for (thread = 0; thread < thread_count; thread++)
pthread_create(&thread_handles[thread], NULL,
Hello, (void*) thread);
printf("Hello from the main thread\n");
for (thread = 0; thread < thread_count; thread++)
pthread_join(thread_handles[thread], NULL);
free(thread_handles);
return 0;
} /* main */
/*-------------------------------------------------------------------*/
void *Hello(void* rank) {
long my_rank = (long) rank; /* Use long in case of 64-bit system */
printf("Hello from thread %ld of %d\n", my_rank, thread_count);
return NULL;
} /* Hello */
/*-------------------------------------------------------------------*/
void Usage(char* prog_name) {
fprintf(stderr, "usage: %s <number of threads>\n", prog_name);
fprintf(stderr, "0 < number of threads <= %d\n", MAX_THREADS);
exit(0);
} /* Usage */
核心代码:
#include // 注意 pthread_create 调用函数必须是
矩阵乘法
总体来说 Pthread 比 OpenMpi 要清爽,不考虑线程之间的通讯的话代码量少很多,更好理解。
就矩阵乘法来说,数据保存都在全局变量不需要传递,只需要传递线程编号 rank 即可,Pthread 核心调用和 “hello,world” 一模一样。
for (thread = 0; thread < thread_count; thread++)
pthread_create(&thread_handles[thread], NULL,
Pth_mat_vect, (void*) thread);
for (thread = 0; thread < thread_count; thread++)
pthread_join(thread_handles[thread], NULL);
π的计算
这算是第一个实用并且比较重要的例子。π的算法很多,这里的计算只是要测试代码能力,不纠结算法效率的差异。
与矩阵乘法不太一样,这里用到的方法可能会对相同的全局变量同时做读写操作,同时的访问,称为
蒙特卡洛方法
蒙特卡洛方法实现计算圆周率的方法比较简单,其思想是假设我们向一个正方形的标靶上随机投掷飞镖,靶心在正中央,标靶的长和宽都是 2 英尺。同时假设有一个圆与标靶内切。圆的半径是 1 英尺,面积是π平方英尺。如果击中点在标靶上是均匀分布的(我们总会击中正方形),那么飞镖击中圆的数量近似满足等式:
飞镖落在圆内的次数
我们可以用这个公式和随机数产生器来估计π的值。
#include<stdlib.h>
#include<stdio.h>
#include<math.h>
#include<pthread.h>
int thread_count;
long long int num_in_circle,n;
pthread_mutex_t mutex;
void* compute_pi(void* rank);
int main(int argc,char* argv[]){
long thread;
pthread_t* thread_handles;
thread_count=strtol(argv[1],NULL,10);
printf("please input the number of point\n");
scanf("%lld",&n);
thread_handles=(pthread_t*)malloc(thread_count*sizeof(pthread_t));
pthread_mutex_init(&mutex,NULL);
for(thread=0;thread<thread_count;thread++)
pthread_create(&thread_handles[thread],NULL,compute_pi,(void*)thread);
for(thread=0;thread<thread_count;thread++)
pthread_join(thread_handles[thread],NULL);
pthread_mutex_destroy(&mutex);
double pi=4*(double)num_in_circle/(double)n;
printf("The esitimate value of pi is %lf\n",pi);
}
void* compute_pi(void* rank){
long long int local_n;
local_n=n/thread_count;
double x,y,distance_squared;
for(long long int i=0;i<local_n;i++){
x=(double)rand()/(double)RAND_MAX;
y=(double)rand()/(double)RAND_MAX;
distance_squared=x*x+y*y;
if(distance_squared<=1){
pthread_mutex_lock(&mutex);
num_in_circle++;
pthread_mutex_unlock(&mutex);
}
}
return NULL;
}
计数的核心代码为:
//pthread_mutex_t mutex; //我们希望一个线程执行num_in_circle++;时,其他线程不能操作,这段代码被称为临界区。
mutex 为 Pthread 定义的互斥量(互斥锁),其作用与更加直观的忙等待效果类似:
while(flag!=my_rank);
num_in_circle++;
flag = (flag+1)% thread_count;
但显然,互斥量的作用机制不需要依赖次序,因此使用互斥量效率更高。尤其当创建线程多于系统并行进程数时,忙等待可能和系统调度冲突造成短暂阻塞。
注意,无法通过以下代码实现互斥量功能:
//int flag = 1;
while(flag!=1);
flag = 0;
num_in_circle++;
flag = 1;
因为对 flag 的赋值操作自身就可能造成竞争条件,导致非预期结果。
π的莱布尼茨公式
由
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <pthread.h>
const int MAX_THREADS = 1024;
long thread_count;
long long n;
double sum;
void* Thread_sum(void* rank);
/* Only executed by main thread */
void Get_args(int argc, char* argv[]);
void Usage(char* prog_name);
double Serial_pi(long long n);
int main(int argc, char* argv[]) {
long thread; /* Use long in case of a 64-bit system */
pthread_t* thread_handles;
/* Get number of threads from command line */
Get_args(argc, argv);
thread_handles = (pthread_t*) malloc (thread_count*sizeof(pthread_t));
sum = 0.0;
for (thread = 0; thread < thread_count; thread++)
pthread_create(&thread_handles[thread], NULL,
Thread_sum, (void*)thread);
for (thread = 0; thread < thread_count; thread++)
pthread_join(thread_handles[thread], NULL);
sum = 4.0*sum;
printf("With n = %lld terms,\n", n);
printf(" Our estimate of pi = %.15f\n", sum);
sum = Serial_pi(n);
printf(" Single thread est = %.15f\n", sum);
printf(" pi = %.15f\n", 4.0*atan(1.0));
free(thread_handles);
return 0;
} /* main */
void* Thread_sum(void* rank) {
long my_rank = (long) rank;
double factor;
long long i;
long long my_n = n/thread_count;
long long my_first_i = my_n*my_rank;
long long my_last_i = my_first_i + my_n;
double my_sum = 0.0;
if (my_first_i % 2 == 0)
factor = 1.0;
else
factor = -1.0;
for (i = my_first_i; i < my_last_i; i++, factor = -factor) {
my_sum += factor/(2*i+1);
}
pthread_mutex_lock(&mutex);
sum += my_sum;
pthread_mutex_unlock(&mutex);
return NULL;
} /* Thread_sum */
double Serial_pi(long long n) {
double sum = 0.0;
long long i;
double factor = 1.0;
for (i = 0; i < n; i++, factor = -factor) {
sum += factor/(2*i+1);
}
return 4.0*sum;
} /* Serial_pi */
void Get_args(int argc, char* argv[]) {
if (argc != 3) Usage(argv[0]);
thread_count = strtol(argv[1], NULL, 10);
if (thread_count <= 0 || thread_count > MAX_THREADS) Usage(argv[0]);
n = strtoll(argv[2], NULL, 10);
if (n <= 0) Usage(argv[0]);
} /* Get_args */
void Usage(char* prog_name) {
fprintf(stderr, "usage: %s <number of threads> <n>\n", prog_name);
fprintf(stderr, " n is the number of terms and should be >= 1\n");
fprintf(stderr, " n should be evenly divisible by the number of threads\n");
exit(0);
} /* Usage */
反正都不怎么精确就是了。
反正切级数欧拉变换
虽然求 pi 的例子能很好地引入互斥量机制,参考 目前求 π 的算法中哪种收敛最快? - byoshovel 的回答 - 知乎,我们使用线性效率的反正切级数欧拉变换公式:
代码自 用 c++
#include
#include
int a[100000];
int main()
{
float s;
int b, x, n, c, i, j, d, l;
scanf("%d",&x);
for (s = 0, n = 1; n <= 5000; n++)
{
s = s + log10((2 * n + 1) / n);
if (s > x + 1)
break;
}
for (i = 0; i <= x + 5; i++)
a[i] = 0;
for (c = 1, j = n; j >= 1; j--) // 这种方法和其他方法,或者无法准确切分数据块让 pthread 处理,或者计算结果依赖前项虽然肯定可以并行化处理,但通常要修改公式,改写成 pthread 并行较为困难。看之后学习有没有办法处理。
信号量(semaphore)
介绍
互斥量是有明显缺点的,我们只能控制临界区每个时刻至多只有一个线程在访问,但不能跨线程控制临界区在我们想执行的时候开始。
当然,使用 while 结构的忙等待机制能够解决这个问题,但忙等待本身效率不高。
荷兰计算机科学家

分析如下代码:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <semaphore.h>
#define BARRIER_COUNT 100
int thread_count;
int counter;
sem_t barrier_sems[BARRIER_COUNT];
sem_t count_sem;
void Usage(char* prog_name);
void *Thread_work(void* rank);
int main(int argc, char* argv[]) {
long thread, i;
pthread_t* thread_handles;
if (argc != 2)
Usage(argv[0]);
thread_count = strtol(argv[1], NULL, 10);
thread_handles = malloc (thread_count*sizeof(pthread_t));
for (i = 0; i < BARRIER_COUNT; i++)
sem_init(&barrier_sems[i], 0, 0);
sem_init(&count_sem, 0, 1);
for (thread = 0; thread < thread_count; thread++)
pthread_create(&thread_handles[thread], (pthread_attr_t*) NULL,
Thread_work, (void*) thread);
for (thread = 0; thread < thread_count; thread++) {
pthread_join(thread_handles[thread], NULL);
}
sem_destroy(&count_sem);
for (i = 0; i < BARRIER_COUNT; i++)
sem_destroy(&barrier_sems[i]);
free(thread_handles);
return 0;
} /* main */
void Usage(char* prog_name) {
fprintf(stderr, "usage: %s <number of threads>\n", prog_name);
exit(0);
} /* Usage */
void *Thread_work(void* rank) {
long my_rank = (long) rank;
int i, j;
for (i = 0; i < BARRIER_COUNT; i++) {
sem_wait(&count_sem);
if (counter == thread_count - 1) {
counter = 0;
sem_post(&count_sem);
for (j = 0; j < thread_count-1; j++)
sem_post(&barrier_sems[i]);
} else {
counter++;
sem_post(&count_sem);
sem_wait(&barrier_sems[i]);
}
if (my_rank == 0) {
printf("All threads completed barrier %d\n", i);
fflush(stdout);
}
}
return NULL;
} /* Thread_work */
其中与信号量有关的核心代码为:
//#include <semaphore.h>
//sem_t barrier_sems[BARRIER_COUNT];
//sem_t count_sem;
//sem_init(&barrier_sems[i], 0, 0); 第三个参数代表初始值
//sem_init(&count_sem, 0, 1);
//sem_destroy();
for (i = 0; i < BARRIER_COUNT; i++) {
sem_wait(&count_sem);
if (counter == thread_count - 1) {
counter = 0;
sem_post(&count_sem);
for (j = 0; j < thread_count-1; j++)
sem_post(&barrier_sems[i]);
} else {
counter++;
sem_post(&count_sem);
sem_wait(&barrier_sems[i]);
}
if (my_rank == 0) {
printf("All threads completed barrier %d\n", i);
fflush(stdout);
}
其中sem_tunsigned int,sem_post()sem_wait(&sem)
因此这段代码将0~thread_count - 2sem_wait(&count_sem);和sem_post(&count_sem);一一对应,用于控制更改 counter 值的这一个临界区。
生产者-消费者同步模型
以下内容来自 经典并发同步模式:生产者-消费者设计模式 | 知乎
什么是生产者-消费者模型
比如有两个进程 A 和 B,它们共享一个固定大小的缓冲区,A 进程产生数据放入缓冲区,B 进程从缓冲区中取出数据进行计算,那么这里其实就是一个生产者和消费者的模型,A 相当于生产者,B 相当于消费者。
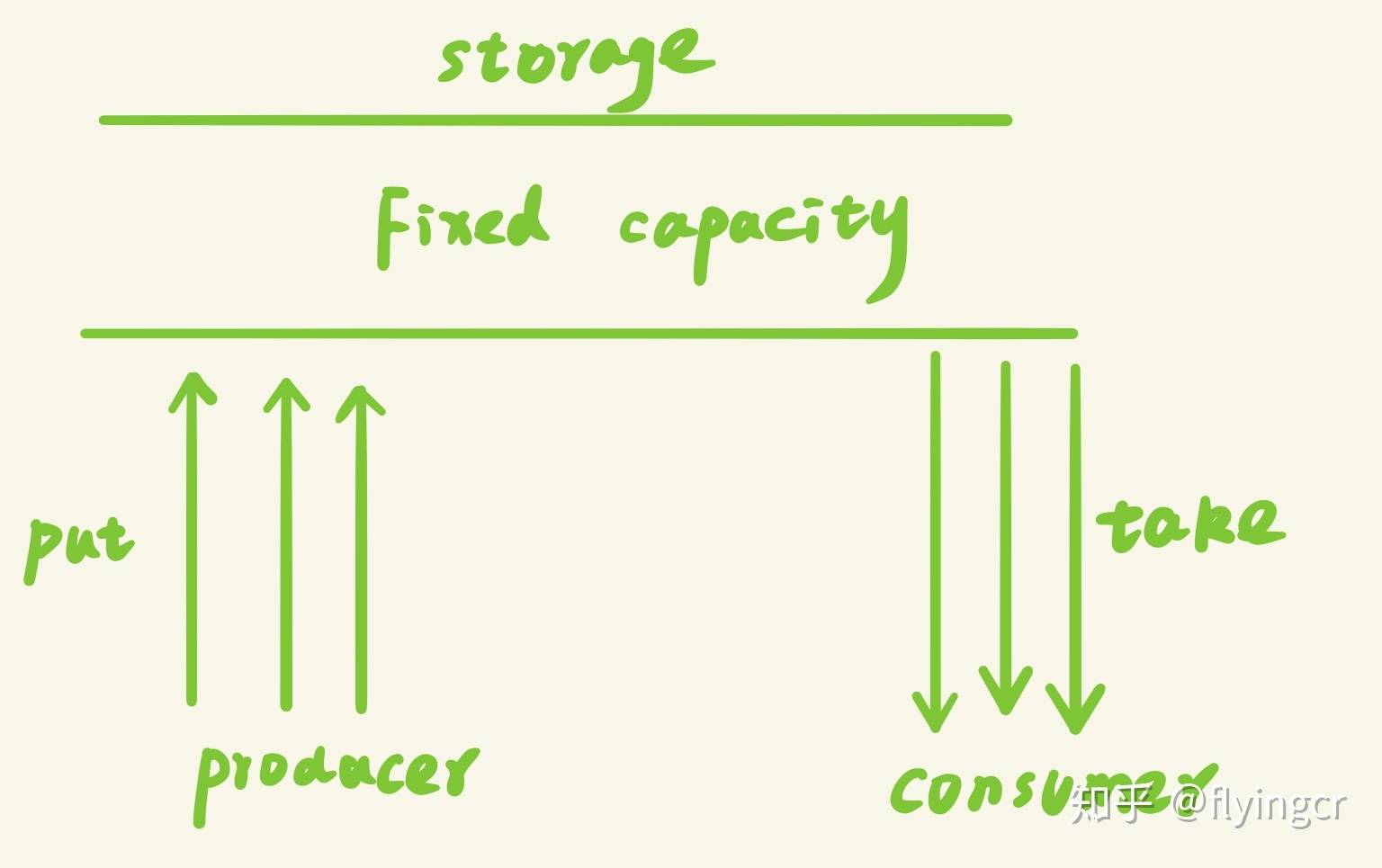
为什么要使用生产者消费者模型
在多线程开发中,如果生产者生产数据的速度很快,而消费者消费数据的速度很慢,那么生产者就必须等待消费者消费完了数据才能够继续生产数据,因为生产那么多也没有地方放啊;同理如果消费者的速度大于生产者那么消费者就会经常处理等待状态,所以为了达到生产者和消费者生产数据和消费数据之间的平衡,那么就需要一个缓冲区用来存储生产者生产的数据,所以就引入了生产者-消费者模型。
生产者-消费者模型的特点
- 保证生产者不会在缓冲区满的时候继续向缓冲区放入数据,而消费者也不会在缓冲区空的时候,消耗数据
- 当缓冲区满的时候,生产者会进入休眠状态,当下次消费者开始消耗缓冲区的数据时,生产者才会被唤醒,开始往缓冲区中添加数据;当缓冲区空的时候,消费者也会进入休眠状态,直到生产者往缓冲区中添加数据时才会被唤醒
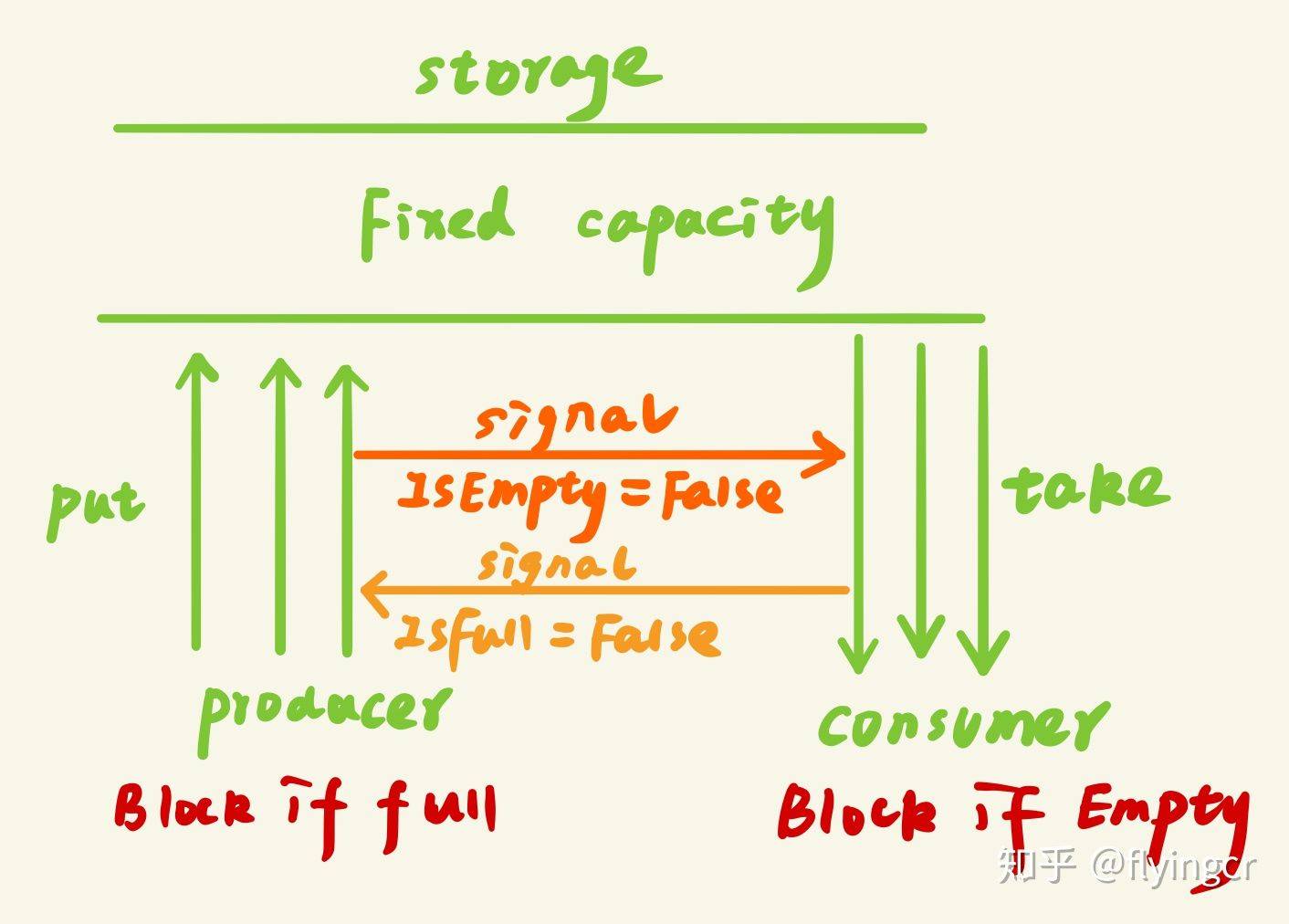
生产者-消费者模型的应用场景生产者-消费者模型的应用场景
生产者-消费者模型一般用于将生产数据的一方和消费数据的一方分割开来,将生产数据与消费数据的过程解耦开来
Excutor 任务执行框架:
- 通过将任务的提交和任务的执行解耦开来,提交任务的操作相当于生产者,执行任务的操作相当于消费者
- 例如使用 Excutor 构建 web 服务器,用于处理线程的请求:生产者将任务提交给线程池,线程池创建线程处理任务,如果需要运行的任务数大于线程池的基本线程数,那么就把任务扔到阻塞队列(通过线程池
+ 阻塞队列的方式比只使用一个阻塞队列的效率高很多,因为消费者能够处理就直接处理掉了,不用每个消费者都要先从阻塞队列中取出任务再执行)
消息中间件 activeMQ:
- 双十一的时候,会产生大量的订单,那么不可能同时处理那么多的订单,需要将订单放入一个队列里面,然后由专门的线程处理订单。这里用户下单就是生产者,处理订单的线程就是消费者;再比如 12306 的抢票功能,先由一个容器存储用户提交的订单,然后再由专门处理订单的线程慢慢处理,这样可以在短时间内支持高并发服务
任务的处理时间比较长的情况下:
- 比如上传附近并处理,那么这个时候可以将用户上传和处理附件分成两个过程,用一个队列暂时存储用户上传的附近,然后立刻返回用户上传成功,然后有专门的线程处理队列中的附近
生产者-消费者模型的优点
- 解耦:将生产者类和消费者类进行解耦,消除代码之间的依赖性,简化工作负载的管理
- 复用:通过将生产者类和消费者类独立开来,那么可以对生产者类和消费者类进行独立的复用与扩展
- 调整并发数:由于生产者和消费者的处理速度是不一样的,可以调整并发数,给予慢的一方多的并发数,来提高任务的处理速度
- 异步:对于生产者和消费者来说能够各司其职,生产者只需要关心缓冲区是否还有数据,不需要等待消费者处理完;同样的对于消费者来说,也只需要关注缓冲区的内容,不需要关注生产者,通过异步的方式支持高并发,将一个耗时的流程拆成生产和消费两个阶段,这样生产者因为执行 put() 的时间比较短,而支持高并发
- 支持分布式:生产者和消费者通过队列进行通讯,所以不需要运行在同一台机器上,在分布式环境中可以通过 redis 的 list 作为队列,而消费者只需要轮询队列中是否有数据。同时还能支持集群的伸缩性,当某台机器宕掉的时候,不会导致整个集群宕掉
(引用结束)
在我们的例子中,信号量的值可看作生产者数量,sem_wait(&count_sem);代表等待的消费者和消费过程。
互斥量和信号量的比较
互斥量和信号量的区别
参考 semaphore 和 mutex 的区别? | 知乎 一句话概括(来自 二律背反):
互斥量 (mutex):保护共享资源。
信号量 (semaphore):调度线程。
用互斥量实现生产者-消费者模型
尽管生产者-消费者同步采用信号量很容易实现,但它也能用互斥量来实现。基本的想 法是:让生产者线程和消费者线程共享一个互斥量。用一个被主线程初始化为 false 的 标志变量来表示是否有产品可以被
void *Thread_work(void* rank) {
long my_rank = (long) rank;
int send = 0, recv = 0;
while(1) {
pthread_mutex_lock(&mutex);
if(msg) {
if (my_rank == receiver && !recv) {
//如果消费者线程首先进入循环,它会看到没有可用的信息 (message_available 值为 false) 并在调用 pthread_mutex_unlock 后返回。消费者线程重复上述过程,直到生产者线程生产出信息。
我们给出每个线程都生产一次,消费一次的核心代码:
void *Thread_work(void* rank) {
long my_rank = (long) rank;
int send = 0, recv = 0;
while(1) {
pthread_mutex_lock(&mutex);
if(msg) {
//路障和条件变量
Pthreads 中实现路障的最好方式之一是条件变量。基本实现如图所示:

当然条件变量也要初始化和销毁,与互斥量的调用方法类似。官方文档如下:
#include <semaphore.h>
初始化条件变量:int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr);
该函数第一个参数为条件变量指针,第二个参数为条件变量属性指针(一般设为 NULL)。该函数按照条件变量属性对条件变量进程初始化。
无条件等待:int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
该函数第一个参数为条件变量指针,第二个为互斥量指针。该函数调用前,需本线程加锁互斥量,加锁状态的时间内函数完成线程加入等待队列操作 ,线程进入等待前函数解锁互斥量。在满足条件离开 pthread_cond_wait 函数之前重新获得互斥量并加锁,因此,本线程之后需要再次解锁互斥量。
通知一个线程:int pthread_cond_signal(pthread_cond_t *cond);
该函数的参数为条件变量指针。该函数向队列第一个等待线程发送信号,解除这个线程的阻塞状态。
通知所有线程:int pthread_cond_broadcast(pthread_cond_t *cond);
该函数的参数为条件变量指针。该函数想队列所有等待线程发送信号,解除这些线程的阻塞状态。
销毁条件变量:int pthread_cond_destroy(pthread_cond_t *cond);
该函数销毁条件变量。
多线程链表和 Pthreads 读写锁
多线程链表的不同实现
考虑一个不降序列链表查找,加入和删除的实现,再多线程调用时,每个位置应该只有一个线程访问,我们可以把整个链表作为一个临界区(实际上是串行),也可以为每个节点设置独立的互斥量和临界区。
但如果我们区分读写操作,那么每个位置可以同时被多个线程读取,因此可以引入更有效率的
以下是读写锁在多线程链表上的实现:
#include
pthread_rwlock_t rwlock;
pthread_rwlock_init(&rwlock,NULL);
// 多个线程能通过调用读锁函数而同时获得锁,但只有一个线程能通过写锁函数获得锁。因此,如果任何线程拥有了读锁,则任何请求写锁的线程将阻塞在写锁函数的调用上。而且,如果任何线程拥有了写锁,则任何想获取读或写锁的线程将阻塞在它们对应的锁函数上。
不同实现方案的开销分析
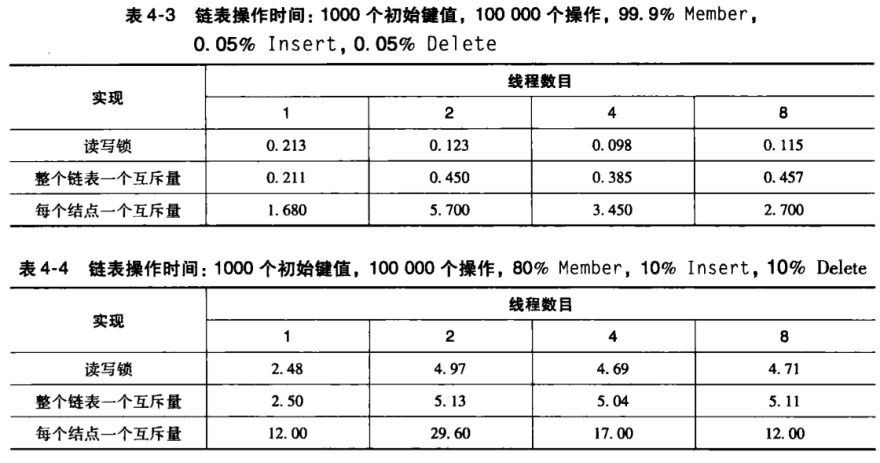
可以看出,过多的枷锁和解锁开销过大,而并行使用读写锁在 Member 占比极大时才优于串行实现的方案。
线程安全性
线程安全是程式设计中的术语,指某个函数、函数库在多线程环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能正确完成。
假设有间银行只有 1000 元,而两个人同时提领 1000 元时就可能会拿到总计 2000 元的金额。为了避免这个问题,该间银行提款时应该使用互斥锁,即意味着针对同一个资源处理时,前一个人提领交易完成后才处理下一笔交易。但这种手法会使得效能降低。
一般来说,线程安全的函数应该为每个调用它的线程分配专门的空间,来储存需要单独保存的状态(如果需要的话),不依赖于
“线程惯性”,把多个线程共享的变量正确对待(如,通知编译器该变量为 “易失(volatile)” 型,阻止其进行一些不恰当的优化),而且,线程安全的函数一般不应该修改全局对象。 很多 C 库代码(比如某些
** strtok ** 的实现,它将 “多次调用中需要保持不变的状态” 储存在静态变量中,导致不恰当的共享)不是线程安全的,在多线程环境中调用这些函数时,要进行特别的预防措施,或者寻找别的替代方案。
下面给出 c 语言的线程安全函数和非线程安全函数。(来自 Thread-safe C library functions 和 C library functions that are not thread-safe)
Thread-safe C library functions
The following table shows the C library functions that are thread-safe.
| Functions | Description |
|---|---|
calloc(), free(), malloc(), realloc() | The heap functions are thread-safe if the _mutex_* functions are implemented.All threads share a single heap and use mutexes to avoid data corruption when there is concurrent access. Each heap implementation is responsible for doing its own locking. If you supply your own allocator, it must also do its own locking. This enables it to do fine-grained locking if required, rather than protecting the entire heap with a single mutex (coarse-grained locking). |
alloca() | alloca() is thread-safe because it allocates memory on the stack. |
abort(), raise(), signal(), fenv.h | The ARM® signal handling functions and floating-point exception traps are thread-safe.The settings for signal handlers and floating-point traps are global across the entire process and are protected by locks. Data corruption does not occur if multiple threads call signal() or an fenv.h function at the same time. However, be aware that the effects of the call act on all threads and not only on the calling thread. |
clearerr(), fclose(), feof(),ferror(), fflush(), fgetc(),fgetpos(), fgets(), fopen(),fputc(), fputs(), fread(),freopen(), fseek(), fsetpos(),ftell(), fwrite(), getc(),getchar(), gets(), perror(),putc(), putchar(), puts(),rewind(), setbuf(), setvbuf(),tmpfile(), tmpnam(), ungetc() | The stdio library is thread-safe if the _mutex_* functions are implemented.Each individual stream is protected by a lock, so two threads can each open their own stdio stream and use it, without interfering with one another.If two threads both want to read or write the same stream, locking at the fgetc() and fputc() level prevents data corruption, but it is possible that the individual characters output by each thread might be interleaved in a confusing way.Notetmpnam() also contains a static buffer but this is only used if the argument is NULL. To ensure that your use of tmpnam() is thread-safe, supply your own buffer space. |
fprintf(), printf(), vfprintf(), vprintf(), fscanf(), scanf() | When using these functions:The standard C printf() and scanf() functions use stdio so they are thread-safe.The standard C printf() function is susceptible to changes in the locale settings if called in a multithreaded program. |
clock() | clock() contains static data that is written once at program startup and then only ever read. Therefore, clock() is thread-safe provided no extra threads are already running at the time that the library is initialized. |
errno | errno is thread-safe.Each thread has its own errno stored in a __user_perthread_libspace block. This means that each thread can call errno-setting functions independently and then check errno afterwards without interference from other threads. |
atexit() | The list of exit functions maintained by atexit() is process-global and protected by a lock.In the worst case, if more than one thread calls atexit(), the order that exit functions are called cannot be guaranteed. |
abs(), acos(), asin(),atan(), atan2(), atof(),atol(), atoi(), bsearch(),ceil(), cos(), cosh(),difftime(), div(), exp(),fabs(), floor(), fmod(),frexp(), labs(), ldexp(),ldiv(), log(), log10(),memchr(), memcmp(), memcpy(),memmove(), memset(), mktime(),modf(), pow(), qsort(),sin(), sinh(), sqrt(),strcat(), strchr(), strcmp(),strcpy(), strcspn(), strlcat(),strlcpy(), strlen(), strncat(),strncmp(), strncpy(), strpbrk(),strrchr(), strspn(), strstr(),strxfrm(), tan(), tanh() | These functions are inherently thread-safe. |
longjmp(), setjmp() | Although setjmp() and longjmp() keep data in __user_libspace, they call the __alloca_* functions, that are thread-safe. |
remove(), rename(), time() | These functions use interrupts that communicate with the ARM debugging environments. Typically, you have to reimplement these for a real-world application. |
snprintf(), sprintf(), vsnprintf(),vsprintf(), sscanf(), isalnum(),isalpha(), iscntrl(), isdigit(),isgraph(), islower(), isprint(),ispunct(), isspace(), isupper(),isxdigit(), tolower(), toupper(),strcoll(), strtod(), strtol(),strtoul(), strftime() | When using these functions, the string-based functions read the locale settings. Typically, they are thread-safe. However, if you change locale in mid-session, you must ensure that these functions are not affected.The string-based functions, such as sprintf() and sscanf(), do not depend on the stdio library. |
stdin, stdout, stderr | These functions are thread-safe. |
C library functions that are not thread-safe
The following table shows the C library functions that are not thread-safe.
| Functions | Description |
|---|---|
asctime(), localtime(), strtok() | These functions are all thread-unsafe. Each contains a static buffer that might be overwritten by another thread between a call to the function and the subsequent use of its return value.ARM® supplies reentrant versions, _asctime_r(), _localtime_r(), and _strtok_r(). ARM recommends that you use these functions instead to ensure safety.NoteThese reentrant versions take additional parameters. _asctime_r() takes an additional parameter that is a pointer to a buffer that the output string is written into. _localtime_r() takes an additional parameter that is a pointer to a struct tm, that the result is written into. _strtok_r() takes an additional parameter that is a pointer to a char pointer to the next token. |
exit() | Do not call exit() in a multithreaded program even if you have provided an implementation of the underlying _sys_exit() that actually terminates all threads.In this case, exit() cleans up before calling _sys_exit() so disrupts other threads. |
gamma(), lgamma(), lgammaf(), lgammal() | These extended mathlib functions use a global variable, _signgam, so are not thread-safe. |
mbrlen(), mbsrtowcs(), mbrtowc(), wcrtomb(), wcsrtombs() | The C90 multibyte conversion functions (defined in stdlib.h) are not thread-safe, for example mblen() and mbtowc(), because they contain internal static state that is shared between all threads without locking.However, the extended restartable versions (defined in wchar.h) are thread-safe, for example mbrtowc() and wcrtomb(), provided you pass in a pointer to your own mbstate_t object. You must exclusively use these functions with non-NULL mbstate_t * parameters if you want to ensure thread-safety when handling multibyte strings. |
rand(), srand() | These functions keep internal state that is both global and unprotected. This means that calls to rand() are never thread-safe.ARM recommends that you do one of the following:Use the reentrant versions _rand_r() and _srand_r() supplied by ARM. These use user-provided buffers instead of static data within the C library.Use your own locking to ensure that only one thread ever calls rand() at a time, for example, by defining rand() if you want to avoid changing your code.Arrange that only one thread ever needs to generate random numbers.Supply your own random number generator that can have multiple independent instances.Note_rand_r() and _srand_r() both take an additional parameter that is a pointer to a buffer storing the state of the random number generator. |
setlocale(), localeconv() | setlocale() is used for setting and reading locale settings. The locale settings are global across all threads, and are not protected by a lock. If two threads call setlocale() to simultaneously modify the locale settings, or if one thread reads the settings while another thread is modifying them, data corruption might occur. Also, many other functions, for example strtod() and sprintf(), read the current locale settings. Therefore, if one thread calls setlocale() concurrently with another thread calling such a function, there might be unexpected results.Multiple threads reading the settings simultaneously is thread-safe in simple cases and if no other thread is simultaneously modifying those settings, but where internally an intermediate buffer is required for more complicated returned results, unexpected results can occur unless you use a reentrant version of setlocale().ARM recommends that you either:Choose the locale you want and call setlocale() once to initialize it. Do this before creating any additional threads in your program so that any number of threads can read the locale settings concurrently without interfering with one another.Use the reentrant version _setlocale_r() supplied by ARM. This returns a string that is either a pointer to a constant string, or a pointer to a string stored in a user-supplied buffer that can be used for thread-local storage, rather than using memory within the C library. The buffer must be at least _SETLOCALE_R_BUFSIZE bytes long, including space for a trailing NUL.Be aware that _setlocale_r() is not fully thread-safe when accessed concurrently to change locale settings. This access is not lock-protected.Also, be aware that localeconv() is not thread-safe. Call the ARM function _get_lconv() with a pointer to a user-supplied buffer instead. |
参考资料
并行计算导论。Introduction to Parallel Computing. Ananth Grama.